Introduction
Here at Functori, cybersecurity isn't just a priority — it's at the core of everything we do. We're dedicated to delivering unparalleled security across all fronts. From meticulous auditing to the innovative development of our APIs, smart contracts, backend, and frontend systems, we utilize various sophisticated techniques, including formal methods, thorough manual reviews, and comprehensive testing. It is within this context that our interest in fuzzing has grown substantially.
Fuzzing, often referred to as fuzz testing, is a method of automated testing aimed at exploring a program's execution paths. This technique involves supplying the program with a wide range of inputs and monitoring the effects these inputs have on the program's behavior.
First, let's take a closer look at how and where a fuzzer gets the inputs it uses. We mentioned earlier that fuzzing is all about being automated, so ideally, a fuzzer has to generate its own inputs.
Let's break down the three main ways fuzzers do this.
First up are the "naive” fuzzers, which generate inputs randomly.
Unfortunately, these fuzzers tend to be fairly inefficient, since a significant number of generated inputs are rejected by the program under test.
More efficient fuzzers can be classed as either mutation-based or grammar-based.
Mutation-based fuzzers mutate (i.e. modify) their inputs. The idea is that if you have a valid input and you modify it slightly, it will still remain valid. Ideally, these fuzzers start off with an initial set of inputs provided by the user, called a seed, as a basis for their mutations.
An example of a mutation-based fuzzer is AFL.
Grammar-based fuzzers rely on an input grammar, which serves as a blueprint, defining the syntactic rules for constructing inputs.
Using grammar is especially effective for systematic and efficient input generation when dealing with complex input formats. An example of a grammar-based fuzzer is RESTler, a REST API fuzzer developed by Microsoft. RESTler relies on Hypothesis Testing to generate random data using an input grammar and statistics.
Below is a picture explaining the various stages of a fuzzer.
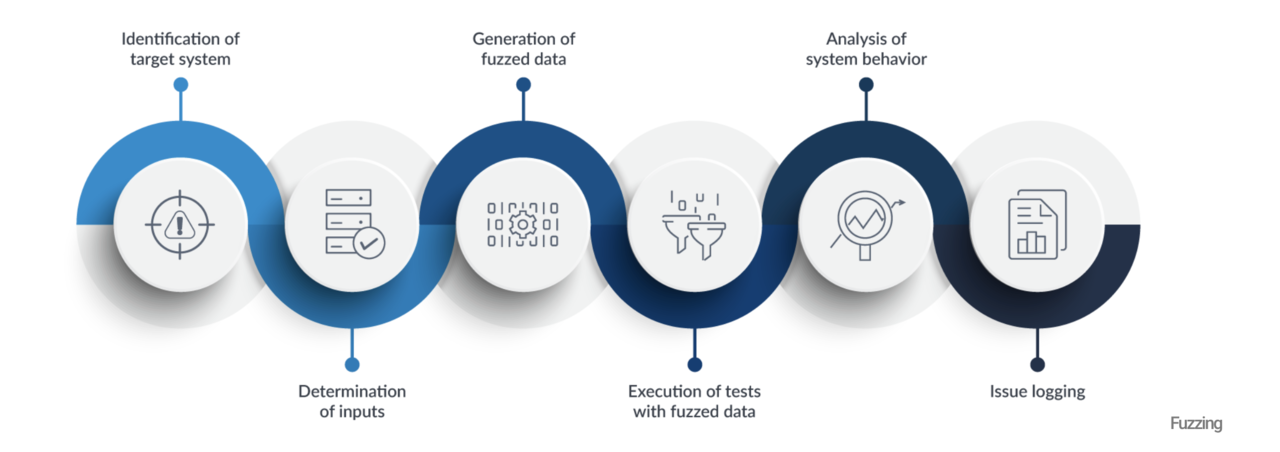 Source: "What is Fuzzing? - Another good way to do smart testing"
Source: "What is Fuzzing? - Another good way to do smart testing"
Fuzzer Types
As with testing in general, fuzzers can also be separated into three
categories: black-box, white-box, and grey-box.
First up are white-box fuzzers. These fuzzers have access to the source code of the program under test and employ heavyweight techniques like symbolic execution to explore execution paths. An example of this type of fuzzer is SAGE, developed by Microsoft.
Next are black-box fuzzers.
These are the simplest of the three. Black-box fuzzers have no knowledge of the source code, and are only able to observe a program’s behavior.
Examples of this type of fuzzers are API fuzzers, such as RESTler mentioned earlier, or Schemathesis, a REST API fuzzer.
Finally, grey-box fuzzers are everything that lies in between. Unlike black-box fuzzers, grey-box fuzzers are not completely oblivious to the source code, however they do not reason about the code itself like white-box fuzzers do.
For example, grey-box fuzzers can dynamically gather feedback while a program runs, such as code coverage.
AFL is an example of a grey-box fuzzer.
Here is a chart that outlines the different classifications of fuzzers as discussed above:
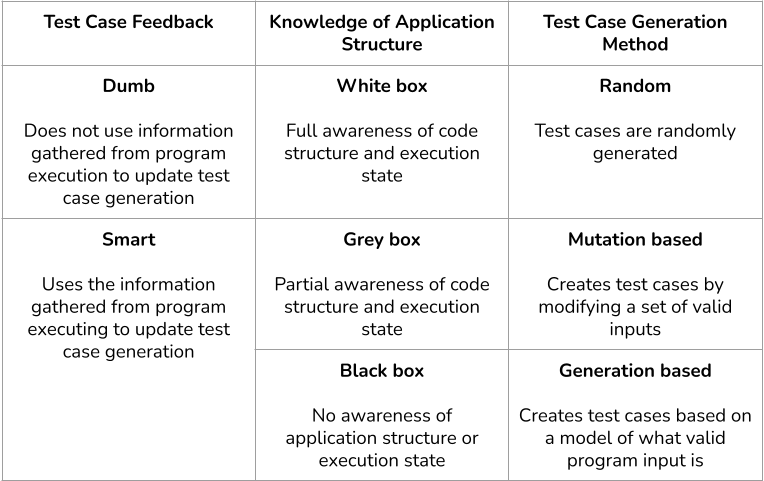 Source: The various ways in which a fuzzer can be classified.
Source: The various ways in which a fuzzer can be classified.
Bugs
Different fuzzers can target different bugs/vulnerabilities.
For example, fuzzers can be used in a type of test called penetration testing (pentesting), the aim of which is to detect the various vulnerabilities that an attacker can exploit to obtain unauthorized access to a system. These vulnerabilities include buffer overflows, SQL injections, command injections, leaks of sensitive information, inadequate input validation, denial of service (DoS), attacks on protocols, etc.
Conclusion
In conclusion, fuzzing is essential in the development cycle. By randomly evaluating programs, fuzzing not only tests functionality, but also enhances software security by detecting a wide range of vulnerabilities. The choice between data mutation and grammatical fuzzing offers flexibility in input generation, while white-box, black-box and grey-box fuzzers provide approaches tailored to different situations. Stay tuned for upcoming articles about our take on API fuzzing.